AWS LambdaのRuby .zipパッケージでgitから取得したgemを使う
AWS LambdaでRubyランタイムを使っててzipアーカイブで関数コードをアップロードしてる人向け。
基本的にはGemfileに依存関係書いてbundle config set --local path 'vendor/bundle'してbundle installすればいい。以下のドキュメントを読もう。
んだけど、Gemfileにrubygems.org以外から取得したgem、特にgitを指定したものを使っている場合にこれだけだとうまくいかないので、原因と対処を書いておく。
そもそもLambdaは何をやってるか
上述ドキュメントを読むとわかるが、zipファイルにはGemfile.lockもGemfileも入れない。それで動作する。これはどういうことかというと、AWS Lambdaのランタイム側ではBundlerを使わず(?)、vendor/bundle 以下にLambdaが想定しているパスで置かれているファイルを直接探索するように$LOAD_PATHが指定されてるんじゃないかと思う。*1
で、通常rubygems.orgから取得したgemについては vendor/bundle/ruby/3.2.0/gems/ 以下にmyclient-1.1.0みたいなディレクトリでコード等が展開される。またvendor/bundle/ruby/3.2.0/specifications/ ディレクトリにgemspecファイルがmyclient-1.1.0.gemspecとして置かれる。試してみていた範囲では、gemspecを検出したらそれに対応するgemのディレクトリを$LOAD_PATHに追加してるんじゃないかと思う。
gitから取得したgemの扱い
gitから取得したgemについてはBundlerはrubygems.orgからのものとは異なり、vendor/bundle/ruby/3.2.0/bundler/gems/以下にmyclient-xxxxxxxのようなディレクトリで展開される。xxxxxの部分はcommit hash。
これはLambdaランタイムが読み込むディレクトリと異なっているため、zipファイルに含まれていても実行時にロードパスが通らず、requireしてもエラーになる。なんということでしょう。
無理矢理パスを通す
しょうがないので、以下のようにしてzipアーカイブを作れば動くようになる。
1. ruby/3.2.0/gems以下にシンボリックリンクを作成する
bundle installしてgitから取得したgemが展開されたら、そのディレクトリに対して以下のようにシンボリックリンクを作る。
$ ln -s vendor/bundle/ruby/3.2.0/bundler/gems/myclient-xxxxxx vendor/bundle/ruby/3.2.0/gems/myclient-1.1.0
こうすれば手元で実行するときにも壊れない。zipアーカイブを作るときは*2シンボリックリンクだった部分はそこにコピーされたようになるはず。つまり、Lambda環境ではruby/3.2.0/gems以下に該当gemのコピーが展開される。
2. specifications以下にgemspecをコピーする
gemspecがないと動かないのでこれもオリジナルの場所からコピーする。コピー時にバージョン番号をつけたファイルにするのに注意。
$ cp vendor/bundle/ruby/3.2.0/bundler/gems/myclient-xxxxx/myclient.gemspec vendor/bundle/ruby/3.2.0/specifications/myclient-1.1.0.gemspec
(余談) pathで指定したgemはどうなる?
Gemfileではgitで指定する他にもpathでローカルパスにあるgemを使うよう指定できる。開発中のgemを直接使うときに便利。
が、この指定だとBundlerは該当パスを直接見に行ってライブラリをロードし、vendor/bundle以下にはコピーを作らない。このため、zipアーカイブにしようとしても入ってくれず、Lambdaランタイム上では使いようがないということになる。
ローカルストレージ上のものをコピーしてzipアーカイブに入れてもいいけど、何が起きるかちょっとわからないのが怖い気もするので、開発中とはいえgitリポジトリ経由で入れるようにしたほうがいいかなと思います。
PathtraqというLifeLogサービスを作った
最近何をやっていたかというと、タイトルの通り、Pathtraqというサービス、iPhoneアプリを作っていた。どんなサービスかと聞かれるとLifeLogというのが一番適切だと思うけど、LifeLogにも種類があって、これは位置情報を記録して検索するサービスになる。

どういうためのものかというと、普段生活したりどこかに行ったりして、以下のようなことが気になる方向けです。
- この場所/店/街、最後に来たのいつだっけ?
- 前に飲みにいってふらっと入ったあの店、どこにあった何ていう店だっけ?
- 前にあそこからあっちに移動したとき、どのくらい時間かかったっけ?
なんかさあ、この程度のこと、全部記録とってあれば簡単にわかるはずなんだけど、いまいちそうなってない*1。いいかげん解決されてくれよ、2023年だぞ! という気分で作った。
このアプリは基本的にバックグラウンドで動作して、自分がどこにいたのかを、24時間・365日記録する。もちろん記録するだけじゃ役に立たないので、時間を指定していつからいつまでの間にどこからどこまでどのように移動したかを表示できるし、場所(エリア)を指定して、その範囲のログはいつ記録されたのか、つまりある場所に行ったのはいつだったかを検索できる。あれこれチューニング頑張ったので、同様の機能*2に較べて高精度のログが、バッテリー負荷低くとれているはず。
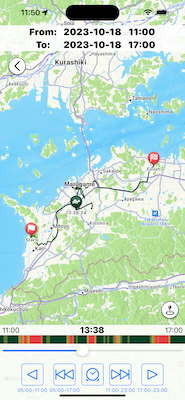
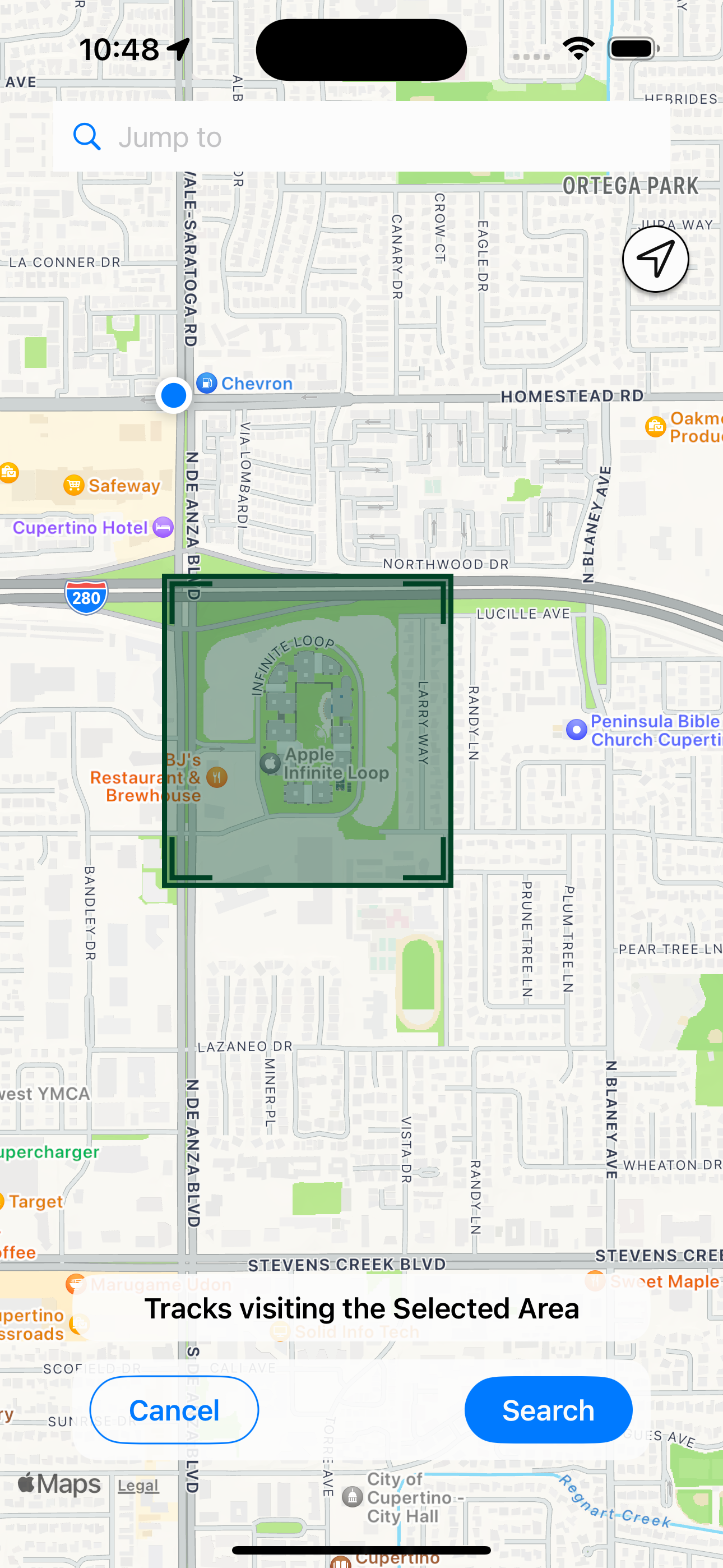
あとはお決まりのチェックイン。人間は行った場所にチェックインしたい。自分もしたい。あと写真もつけたかったのでつけられるようにした。あまり大量につけられると良からぬことに使われるから、いちおういまは4枚までだけど。
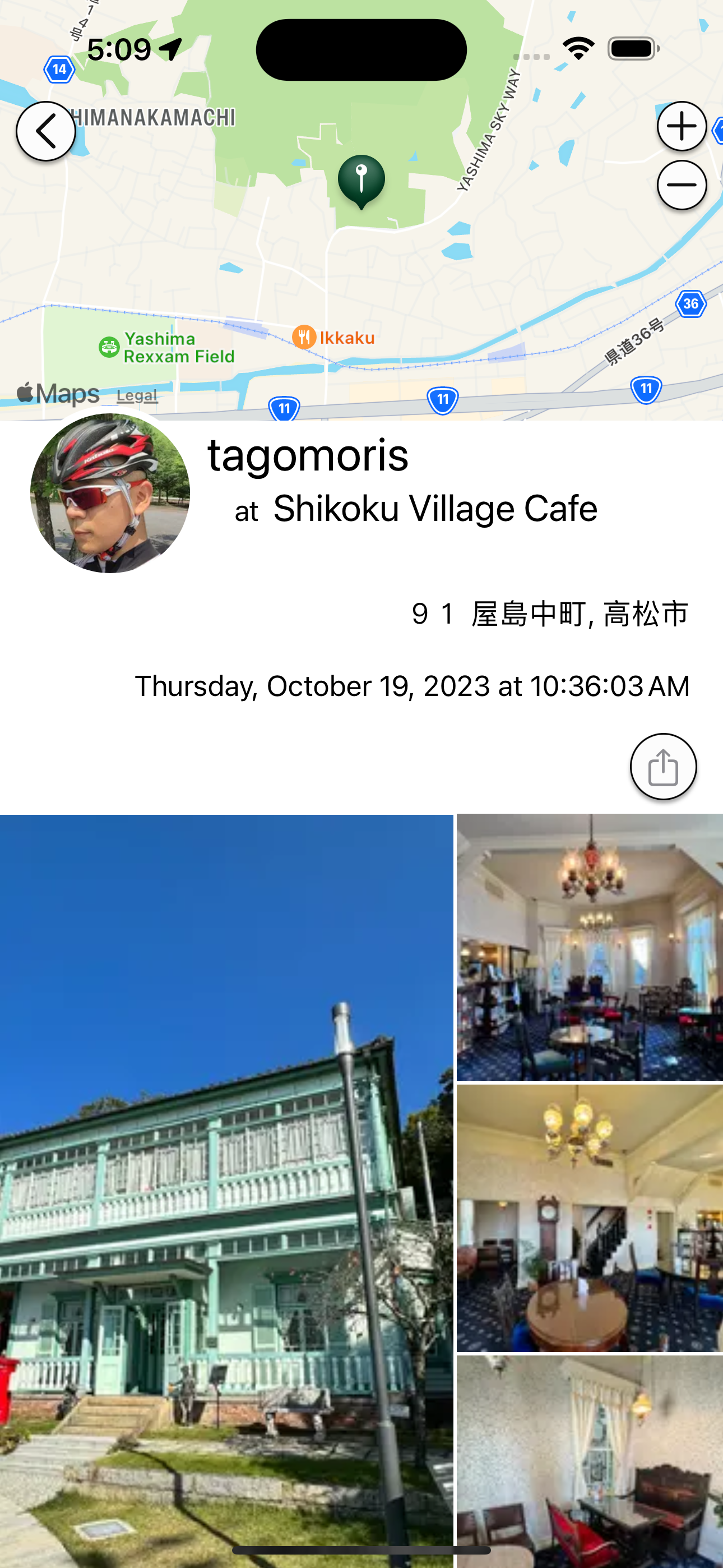
OGP画像生成なんかも頑張ったのでFacebookやXやThreadsにリンクすると格好よく展開される! はず!*3
データはサーバサイドに送って保存してます。写真やチェックイン情報も。いつどこにいたかの情報は、もちろんユーザのもので、必要なときはアーカイブダウンロードできます。やったね。
ということで、興味がある人は使ってみてください! 無料! どうぞ!
データとかどうなるの
いちおうそれなりの知識と経験のあるプログラマだという自負はあって、その自覚と責任のもとで、必要な安全性を担保できる程度にはセキュリティのことを考えて作っています。
またどのBig Techとも関係ない完全に独立したアプリであって、かつ広告なども現状入れておらず、データを個人情報を結び付けることは絶対にしない、というポリシーのもとで作っています。また、データを何らかの形で使用するサービスを作るときには絶対にopt-inとする、というポリシーをもっています。詳しくはFAQをどうぞ。
なぜ作ったの
自分は遠くも近くもあちこち行くのが好きなんだけど、どこに行ったか・いつ行ったか、について、過去のことを正確に思い出せないこともよくある。友人たちと飲みにいったあと、2軒めにふらっと入った店がすごくよかったんだけどしこたま酔っ払ったせいでどこの何という店だったかが正確にはわからない、とか。近所の庭園に散歩に行くのに、前に紅葉がすごくよかったのはいつ頃だったっけ? とか。ひさしぶりの街を歩いてるんだけど色々変わってて、あれー、前に来たのいつだっけ? とか。
もちろん個人でGPSログを記録するだけなら色々方法はあるんだけど、デバイスを持ち歩くには充電に気をつかわないといけなかったり、単にiPhone内に記録するだけだとマシな検索機能を作るのが大変だったり機種変更のときに気を遣うことになったり、あれこれ大変。なので、いつも使ってるスマホ(iPhone)を持ち歩いていれば解決されるようにしたい、というのが動機。
あとはチェックインかな。人間はチェックインしたい。Swarm(旧Foursquare)とかを使ってる人もいるけど、個人的にはゲーミフィケーションがいらないというか、そういうものを見せてほしくないんだよね。チェックインするときは単にチェックインしたい。あと写真を添付したい。Facebookのチェックインが条件にぴったりではあるので使ってたんだけど、Facebookに囲い込まれたまんまなのは嫌だなとちょっと思っていたので、機能をつけた。んでSNS等でシェアしたとき格好がつくようにOGP画像をがんばってみた。
どう作ったの
この記事を読む人は気になっているかも。どうかな。
iPhoneアプリの方は完全にSwiftUIで作った。iOS開発からもだいぶ(12年!)離れてたので、プロトタイプ版(UIKit)のスクラッチからの書きおこしだけ友人に(有償で)お願いして、その上に基本機能を作っていき、目途がついた時点でSwiftUIでのプロダクション版を自分で書きおこした。かなり時間をかけたけど、自分にとって不自然な使い勝手の箇所はだいぶなくなった。
サーバサイドはRuby + AWS Lambdaの完全サーバレス。メンテ作業なんかも全部Lambda経由でやるようにしているので常時稼動してるEC2もコンテナ(ECS/Fargate/EKS)もゼロ。ひとりで作るのにサーバの面倒とか見てらんないし。とはいえ完全Lambdaだとパフォーマンスとか管理とか料金とかが多少心配なところも無くはないので、これはユーザが増えてきたらそのうち考えなおすかもしれない。
Webはあまりないけど、React(create-react-app)でSPA。ただチェックインのWebページにいきなり飛ばれたときにOGP画像出したいとかはあって、そのあたりはちょっと苦労して実装した。だからだいたいはS3ホスティングで済んでるけど、サーバサイドのエンドポイントも多少ある。
これからどうするの
自分で使いたいサービスなので、何があっても当面は運用するつもり。ユーザが(かなり?)増えたら運用や開発体制を何か考える。増えなければ、低コストで運用し続けられるように、特にサーバサイドをシュリンクするとかはあるかもしれない。しばらくは細かい改善と機能追加を続けるつもり。
Androidアプリは直近の計画にはないが、そのうち作れたらいいなー、くらいで考えている。自分でやることにこだわってるわけでもないので、誰かに請負でお願いしてもいいなあ。もし興味のあるAndroidアプリエンジニアの人がいたらご連絡ください。
あとWebページなんかは完全に素人の仕事になっているので、誰かプロのデザイナーさんにいつか頼みたいなーと考えてもいる。これも誰かご興味あればご連絡ください。
まとめ
ゼロ年代の個人ウェブサービス全盛だった頃に自分では何も作らなかったのが、今回真面目に全部自分で作ったので、ちょっとスッキリしたね。フルスタックエンジニアだ!
*1:GoogleMapsのタイムラインは? っていう人がいると思うけど、場所(エリア)から「いつ」を検索することはできない
*2:たとえばGoogle Mapsのタイムライン
iOS17/iPhone15でPhotosPickerItem#loadTransferable(type: Data.self)が動かなくなっていた
まーいけるだろ、と自作アプリが動いていたiPhone14 Pro w/ iOS16をiPhone15 Pro w/ iOS17に移行したところ、ビルドしなおしてインストールしたら普通に動いてたっぽいから油断してたら、タイトルの通りPhotosPickerを使って写真データを取り出してるところが動かなくなってた。 具体的にはこのエントリで書いてたコード。
これの、以下のようなコード。
fileprivate extension PhotosPickerItem { func pictureData() async -> Data? { var transferable: Data? = nil do { transferable = try await self.loadTransferable(type: Data.self) } catch { // log the error return nil }
これを実行するとcatch節で以下のようなエラーが報告された。iOS16 / iPhone14では起きなかったもの*1。
CoreTransferable.TransferableSupportError error 0
で、これ、iPhone15Proのシミュレーターでも起きないんだよね。今のところ実機でしか再現できてない。なんなんでしょう。PhotosPickerの使いかたみたいなのをググると同じようなコードで直接Dataに変換している例が大量に見付かるんだけど、みなさんどうなってるんですかね?
解法?: Transferableな変換先を自分で実装する
よく(Appleのドキュメントでも)見るloadTransferableの変換先といえばImageなんだけど、これだとデータ本体を取り出すことができないので却下。困ったんだけど、自分でTransferableな変換先を実装するしかないかな、ということになった。Appleの以下のドキュメントにある通り。
自分の場合は対応フォーマットとしてJPEG/PNGのデータが取り出せればよかったので、それぞれJPEGの場合とPNGの場合用のTransferableなstructを作って変換を試みたところ、これでiPhone15の実機でも正常に動くようになった。コードは下に載せておく。
直接Dataを取り出すことがなぜ失敗するのかがマジで意味不明だが*2、まあ解決した上にコードも綺麗になったような気がするので良しとする。しっかし何故なんだろう、他の人のは動いてるのかな……。
import PhotosUI fileprivate enum TransferError: Error { case importJpeg case importPng case emptyJpeg case emptyPng } struct PickedJpegImage: Transferable { let data: Data static var transferRepresentation: some TransferRepresentation { DataRepresentation(importedContentType: .image) { data in guard let uiImage = UIImage(data: data) else { throw TransferError.importJpeg } guard let data = uiImage.jpegData(compressionQuality: 1.0) else { throw TransferError.emptyPng } return PickedJpegImage(data: data) } } } struct PickedPngImage: Transferable { let data: Data static var transferRepresentation: some TransferRepresentation { DataRepresentation(importedContentType: .image) { data in guard let uiImage = UIImage(data: data) else { throw TransferError.importPng } guard let data = uiImage.pngData() else { throw TransferError.emptyPng } return PickedPngImage(data: data) } } } fileprivate extension PhotosPickerItem { func pictureData() async -> Data? { do { if self.supportedContentTypes.contains(UTType.jpeg) { guard let p = try await self.loadTransferable(type: PickedJpegImage.self) else { // error log return nil } return p.data } else if self.supportedContentTypes.contains(UTType.png) { guard let p = try await self.loadTransferable(type: PickedPngImage.self) else { // error log return nil } return p.data } else { // unknown type: error log return nil } } catch { // error log } return nil } }
源泉徴収票シリアストーク: 情報の不均衡とうまくつきあう
TL;DR
- 自分の給与額が業界内で高いのか低いのか、知るのは難しい
- 似たような条件の人どうしでうまく匿名化して共有しあえばいいのでは?
- という欲求を満たす源泉徴収票シリアストークという試みを紹介する
- 実際の実行にはレギュレーションが重要です
給与に関する情報の不均衡
給与・所得というやつがあります。生きるのに必要なのはもちろん、たとえば同じ会社や同じ職種・同じ業界の中でどのくらい高い給与・所得を得ているかがある種のバロメーターになって、高い人がエラい、みたいなトンチンカンなことを言い出す人も出てきたりする。もちろん給与が高いからエラいなんてことは絶対にないんだけど、それはそれとして給与は高いほうが嬉しい。
だがしかし、給与額というやつは個人の能力だけではもちろん決まらなくて、儲かっている会社にいるかどうか、所属している会社がどのくらいの給与を払うポリシーなのか、会社内でどのように評価されているか、などに大きく依存する。このため、よっぽど良い知人同士であっても直接に給与額どうしを比較するのはめちゃくちゃな危険を伴い、後々まで有害な影響を残す*1ことが知られている。
とはいえ、そこに情報の不均衡ができる。給与を出す側の人達は、色々な人を見比べて、誰にどの程度の給与を出しているかを知っている。また外部の人材エージェントやヘッドハンターなども知っていることが多い。しかし雇われる側はそう多くの情報を持っておらず、そもそも自分の給与は満足すべきものなのか、それとももっと多い額を望めるものなのか、正確に知ることはまず不可能と言ってもいいだろう。
求める情報を整理して限定する
さて情報の不均衡はあるが、そこで情報を求めるにしても、誰かれ構わず給与額を聞いたって仕方がない。自分と較べるんだから、自分と同じくらいの評価を受けているのではないか、という人の情報を聞いてこそ意味がある。職種・職位でともに似たようなポジションで、転職の際に、まさにその人の替わりとなって入る、くらいだと理想的だ。あるいは、単に自分と似たような技術的知識と経験をもっている、と思われるくらいでも構わないだろう。
また、雑に「年収」と言ったときに人が想像するものが意外に異なっていることもある。多くは税引き前の給与総額を指すだろうが、実際の暮らしぶりは税引き後の金額を見ないとわからない、とする人もいるだろう。しかし税金は家族構成や居住地などに影響を受ける一方、出す側が考慮することは少ない*2だろう。福利厚生などまで考えだすとどんどん話が膨れてしまい、とても公平には考慮できない。
自分はソフトウェアエンジニアのためその事情も考えると、特にシニアになってくると給与以外の収入があることもある。技術書や雑誌原稿の執筆による印税および原稿料、副業としての勤務や顧問業などをもっている人もいる。これらも「その人の収入」としては含まれるだろう。
しかし、考えてみれば、いま求めているのは「自分の給与額を評価するための指標」であって、これは他人が原稿料を稼いでいようが副業をやっていようが、何ひとつ関係がない。福利厚生だって転職先を決めるには必要な情報だろうが、今の給与額の評価には関係がない。
求める情報は源泉徴収票にある
必要な情報とは、つまり、源泉徴収票の「支払い金額」*3である。
自分と同じようなポジションの、あるいは自分と同じような技術・知識を持った人の源泉徴収票において、「支払い金額」にどういう金額が書かれているかが知りたい。個人名として「誰の」は実際には重要ではなく、自分と比較できる人だと分かっていればそれでいい。
源泉徴収票シリアストーク
ここまで書かれているようなことを自分が考えたのは、もう8年以上も前のことだ。そのとき話が合った人達とやったのが「源泉徴収票シリアストーク」である*4。ある夜にこっそりと居酒屋の一室にあつまり、強固なレギュレーションのもと、それぞれの年収を安全に共有した*5。このくらいの人達はだいたいどのくらいの給与を得ているのか、自分はその中で高低どこに位置するのか。
結論としては、実に有意義な試みだった。ものすごく生々しく確実な形で、自分の給与額をどう評価すればよいかの情報を得た。参加者の一人からは、後に、あの情報がその後のキャリア形成に実に役立ったということも聞いた。ということで、他の人も条件が整えられるのであればやるといいのではないかと思う。
このエントリは以後、源泉徴収票シリアストークをどのように開催すればよいかを紹介する。ざっくり言うと、数名で行われる飲み会として実行する。
人選が何よりも重要
とにかく、給与額という比較的センシティブな情報を、匿名化した状況とはいえ、共有してよいという人だけを集める。よい友人関係があることが前提になるだろう。また個人名と給与額の結び付きを推測できる条件はできるだけ無くしたいため、同じ会社の同僚などは避けたほうがよいだろう。
自分と比較できる人たちである、ということも重要な条件である。明らかに自分よりもシニアな人、明らかにジュニアな人と給与額を比較する意味はまったくない。「同じくらいもらっていて不思議ではない人」、業界的あるいは知識・経験的に自分と同格程度であろう、という人たちを集めて行うべきである*6。
あまり少ない人数だと、誰がいくらもらったかの推測が容易になってしまうため、ある程度の人数がいたほうがいい。おそらく6人以上が望ましいだろう。一方、あまり多い人数になると同格で信用できる人を集めるのも難しいし、全員が同じものを同時に見るのも厳しくなる*7。6〜8人程度が最適なのではないだろうか。
レギュレーションを決める
ここに当時使用したレギュレーション実物がある。これはすべて非常に重要なので、表現を変えつつ理由なども含めて解説する。
レギュレーションの主目的は、どの金額が誰のものなのかを分からなくすることにある。情報は安全に共有できなくては意味がなく、どの金額が誰のものかを推測できそうな手がかりは可能な限り潰しておこう。また金額を見る瞬間を全員で同じにすること、見たときのリアクションを全員で統一することも重要で、これによっていつ出た金額が誰のものかを推測する手がかりも潰しておく。
準備
準備は非常に重要である。守れなさそうな人は参加者に入れてはいけない。
- 源泉徴収票 20xx年 のものから「支払い金額」のみを転記する
- 「円」などの表記を入れず、数字のみを書くこと
- ひと目でわかるよう、3桁ごとにカンマを入れること (例: 8,000,000)
- 白い紙にプリンタで、黒で印字すること
- 全員がひと目で見られるよう、数字をできるだけ大きくなるよう印刷すること
- 数字以外の情報は一切書かないこと
共有すべき情報をシンプルかつ確実に定義する。また「ひと目でわかるよう」は重要で、これで全員が同時に金額を理解できるようにする*8。筆跡などの情報を残さないようプリンタでの印刷は当然だ。
- 給与所得のもののみを記載すること
- 原稿料、印税など、主たる給与所得以外のものは含まない
- 20xx年途中での転職などがある場合は合計金額を記載すること
- ただし転職前後で著しく給与が異なる場合や不労期間が含まれる場合などは20xx年末の給与所得基準で善意のもと12ヶ月分の給与になるよう補正をかけてよい
これも共有される情報の定義である。単に守ればよい。
- 白、長形4号の二重封筒に入れること
- ローソンで販売されているものが望ましい
- 紙を入れたら密封すること
- 封筒の外側には一切何も記載しないこと
- 封筒を折り曲げたりしないこと
これは当日、全員分を出したときに区別がつかないようにするため*9。全員が白い封筒なのに一人だけ茶封筒だったりしたら台無しである。こういう細部をきちんと守れてこそ、安全に重要な情報が共有できると言える。
当日の行動
ここからは当日の行動。実行したときは、できるだけ参加者の知人がいなさそうな街の、できるだけ奥まった場所にある、確実にドアつき個室がとれる店を選んで予約した*10。今にして思えば、ドアつき個室でさえあれば店の外で誰と遭遇しても大して問題にはならなかったんじゃないかという気もするが、しかし秘密の会合めいたイベントを開催するにあたっての雰囲気づくりとしては実に良かった。楽しかった。
さて、当日の行動においても、情報を安全に共有するために守るべき点はいくつもある。
- 飲み会終了15分前になったら行動を開始する
- 全員の封筒を取り出し、全員でシャッフルする
これらの事項は単純だが、重要でもある。状況の共有は飲み会の終了直前がよいと思う。見た内容についてお互いに話し合うようなことは何もないし、一人で考える時間をとる方が健全だろう。封筒を全員でシャッフルするのは、もちろん匿名性のためだ。
- 全員の目の届くところでひとつずつ開封する
- このとき、参加者は数字を見たら必ず「ふーむ」と言うこと
- それ以外は口にしないこと
開封時のリアクションを、これらの項目で強制している。強制的に「ふーむ」と言わせることで自分の金額が出てきたときもリアクションのブレをおさえられる*11。これも安全な情報の共有のためには非常に重要。
- 封筒全部を開封したらハサミで細断する
- 店を出たら全員分をコンビニのゴミ箱などで確実に投棄する
- 以降、当日見たことについては口外しないこと
当然である。
給与額がすべてではない、しかしお金は大事
このようにして、安全に、自分の給与額を評価するための指標を手に入れることができる。いい仲間を集められる人は試してみてもよいだろう。
もちろん、給与額がすべてではない。給与額より重要なことはいくらでもある。しかし同時に、被雇用者として働く以上は、あるいはいい人生を送るためにはある程度はお金について考えることは欠かせない。そのための情報を得るひとつの手段として、こういうのもあるよ、という話でした。
*1:人によります。
*2:つまり雇用主からの評価は税引き前の金額に反映されているはず
*3:給与として勤務先から支払われた、一年分の税引き前の総額
*4:当時、ソフトウェア関連の勉強会で 〜 Casual Talk という名前をつけることが多く、それが名前の由来になっている
*5:この安全性のために重要なのがレギュレーションである
*6:自分の場合はソフトウェアエンジニアのコミュニティ内での友人たちのうち、これはという人達で実行した
*7:これは当日の行動として重要な条件である。後述。
*8:例えば数字が小さかったり読みにくかったりすると、よく見ようとする人と見なくても分かってしまった本人の間でリアクションに差が生まれる可能性がある
*9:なぜローソンのものが望ましいという条件をつけたかはもう覚えていない。なんだっけ……たまたま近くにあったのかな。どのコンビニ等でもよいと思うが、どこかのもので統一できれば理想的だろう。
*10:ある冬の日の実行で、あのブリしゃぶは非常においしかった
*11:どうでもいいが、このとき参加者がみんなで「ふーむ」ってtweetしまくってたら、参加者以外がなにやら不穏な空気を感じとったり真似たりしていてちょっと面白かった
Xcode上のSwift(iOS App)プロジェクトでTestsターゲットのみビルドエラーが起きる
iOSアプリを書いてるんだけどちょっと一部(データの変換とかで)ちゃんとユニットテスト書こうかなと思ったりしても、なんか変なエラーが起きてビルドできなかったりする。なんでだよ。
おそらくAWS Amplifyへの依存、およびその依存ライブラリaws-crt-swiftなどが関係している。ちゃんと理屈のついた解決方法はまだ見付かっていない。
Testsターゲットがビルドできない
テストを書くためのTestsターゲット*1をビルドしようとすると、一部の依存関係が見付からないと出る。直接依存関係として指定したものではない。
Xcode : missing required modules: 'AwsCAuth', 'AwsCCal', 'AwsCCommon', 'AwsCHttp', 'AwsCIo', 'AwsCMqtt', 'AwsCSdkUtils'
なんだこれ、と思ってあれこれ調べると、依存ライブラリを全部明示的にリンク対象としてセットすれば解決するぞ、みたいな話を読んだ(だいぶ前のことで、どこを参考にしたか今となっては不明)。 この設定自体はプロジェクトを開いてから TARGETS → Testsターゲットを選択 → "Build Phases" → "Link Binary With Libraries" を開いて、そこで "+" して出てくるもの全部を選択していた。
が、これをやると、今度は次の問題が出た。
XCTestsが見付からない
次は、テストコードファイル(*Tests.swift)の import XCTest 行でエラーが出たり出なかったりするようになった。出るときは "No such module 'XCTest'"。エディタ上のエラーとして、あるいはビルド時のエラーとして出る。以下のようなエラーのこともある気がする。
Cannot load underlying module for 'XCTest'
これが出たり出なかったりで、本当によくわからない。たまにテストが走るまでいくんだけど、いかないときは全然ダメ。Clean Build Folderしてからのビルドなども試したが、そんな単純な方法では回避できなかった。
いくらか調べたところによると、*Tests.swiftファイルがテストじゃない通常ターゲットのビルド対象ファイルに入っているとそういうことが起きる、ことがあるらしいんだけど、自分の手元ではテストファイルが通常ターゲットのビルド対象に入ってたりはしなかった。
最小限の依存ライブラリのみ明示的にリンクする
いくらか試行錯誤したけれど、以下のようにしたら、テスト走行までできるようになった。
- Testsターゲットを新しく作りなおす("Unit Testing Bundle")
- ビルドエラーが出なくなるまで、ライブラリをひとつずつ、テストターゲットの明示的なリンク対象に追加する
自分の場合、以下のものを追加したところでエラーが出なくなった。XCTestが見付からなくなることも(今のところ)ない。

やれやれ。
結論
やれやれ。なんだろうね。ググってもほとんど同じような話が出てこない。
対症療法でしかないんだけど、とりあえずはこんな感じで。
*1:ProjプロジェクトであればProjTestsターゲット
TokyuRuby会議14に参加してしゃべってきた
久し振りに開催されたTokyuRuby会議14に参加した。LTも申し込んでいて通ったので、LTもやってきた。なんかTokyuRuby会議が行われると、イベントが戻ってきたなあ、という気がする。よかった。
しゃべった
LTの内容は最近やっているNameSpaceまわりの話。
5分LTを最後にやったのは2019年のRubyKaigiだった。5分のLTなんて体に染み付いてるから息をするようにやれるじゃろ、と思ったら完全にペースを間違ってぜんぜん終わらなかった。なんてこった。何でも、やらないと衰えるなあ。
話の内容自体は、あとにあった3分追加でしゃべっていい枠で話せて満足。これは引き続きやってて、9月の松江Ruby会議10でも話す予定です。
料理持っていった

今回作って持っていったのはミニチュアおでん、ローストビーフのわさびマリネ。どっちも全部食べてもらったし、おいしかったと何度も言ってもらえて大満足。ミニチュアおでんは大根の型抜きして下茹でしてるところを前日Twitterに放り込んでいたら、あれなんだったんですかって何人もに聞かれたのが狙い通り。
参加した
あとはもう……いつものTokyuRuby会議だったので、何がどうだったとも言いがたいが、RubyKaigiで話せなかったなという人ともけっこう話せたり、今回の自分のネタについても追加で議論する機会が持てたりで、じつによいイベントだった。楽しかったです。
SwiftUI PhotosPickerで選択した項目からJPEG/PNGを取り出す
SwiftUIで作るiOSアプリで、画像を選択し、その画像をどこかにアップロードしたい。アップロード先がHEICに対応してないのでJPEG/PNGあたりのフォーマットでやりたい。
これを考えたとき、iOS 16.0+ ならPhotosPickerが使える。が、実際に選択したあとでどうやってJPEG/PNGのデータを取り出すかにだいぶ悩んだのでメモっておく。他にもっとマトモな方法ないの? と思っている。
PhotosPickerを使う
これは既存のビューでボタンを押すとシートで下から出てくる感じにしたかったので、こんなコードをざっと書けばよい。これは1枚だけ選ばせたい場合で、複数枚選ばせたい場合は呼び出しのシグネチャが少し変わるのに注意。
@State var isPickingPhoto: Bool = false @State var selectedPhotoItem: PhotosPickerItem? = nil var body: some View { AnyView() .sheet(isPresented: $isPickingPhoto) { PhotosPicker( selection: $selectedPhotoItem, matching: .images, preferredItemEncoding: .current, label: { Text("Choose your profile image") } ) .onChange(of: selectedPhotoItem) { photoItem in guard let photoItem else { return } uploadSelectedPhoto(photoItem) } .presentationDetents([.height(280)]) .presentationDragIndicator(.visible) }
んで実際のデータ取り出しおよびアップロードはuploadSelectedPhoto()で行う。
PhotosPickerItemからデータを取り出す
実際にデータを取り出すとき、JPEGかPNGのどちらかが欲しいとする。しかしiPhoneのカメラで撮影した画像はHEICがプライマリの画像形式になっている(ことが多い)ため、JPEGやPNGが欲しい、と指定する必要がある。選択した写真が対応している形式はsupportedContentTypesで取得できる、が、これはUTTypeを返す。
photoItem.supportedContentTypes //=> [UTType.heic, UTType.jpeg]
ところで、PhotosPickerItemから実際に扱うデータの取り出しはloadTransferable(type:)関数で行うが、ここでtypeに指定するのはSwiftの型であってUTTypeでもMIME Typeでもない。
let transferable = try await photoItem.loadTransferable(type: Data.self)
えー、このDataの中身はなんなんだよ、対応しているUTTypeの形式で取り出させてくれよ、と思うが、そのようなAPIがなさそうに見える。本当に?
で、現状どうしているかというと、しょうがないからいちどUIImageを経由している。これ、画像変換が行われちゃってないかなあ、大丈夫? と思うものの、他に方法が見付かっていない。
// JPEGの場合 let data = UIImage(data: transferable)?.jpegData(compressionQuality: 1.0) // PNGの場合 let data = UIImage(data: transferable)?.pngData()
このへんをまとめて、必要な場所で次のようなextensionを書いておいた。Swiftのfileprivate便利だよね。
typealias UploadPictureData = (data: Data, mimeType: String) let PERMITTED_IMAGE_TYPES = [ UTType.jpeg, UTType.png, ] fileprivate extension PhotosPickerItem { func pictureData() async -> UploadPictureData? { var transferable: Data? = nil do { transferable = try await self.loadTransferable(type: Data.self) } catch { // logging return nil } guard let transferable else { // logging return nil } var data: Data? = nil var mimeType: String? = nil if self.supportedContentTypes.contains(UTType.jpeg) { data = UIImage(data: transferable)?.jpegData(compressionQuality: 1.0) mimeType = UTType.jpeg.preferredMIMEType } else if self.supportedContentTypes.contains(UTType.png) { data = UIImage(data: transferable)?.pngData() mimeType = UTType.png.preferredMIMEType } else { // logging return nil } guard let data, let mimeType else { // logging return nil } return (data, mimeType) } }
もうちょっといいやりかた無いもんかなあ。